こんにちは、タナカです。
この記事では、torchvisionのFaster-RCNNにおけるAnchor Generatorの動作を理解することを目的としています。
この記事を書こうと思った理由は、物体検出で使われているAnchorという概念を理解したいと考えたからです。
実際にコードを動かしながら、中で何が行われているか確認しました。
Anchor Generatorの動作内容がわかる
1. 動作環境
動作環境は下記になります。
torch 1.9.0
torchvision 0.10.0
2. Anchorとは
まず初めに、Anchorについて説明しておきます。Anchorとは、Anchor Boxの中心となる座標になります。Anchor Boxとは物体を検出するために使用される矩形のことを言います。
図で示すとこのようになります。
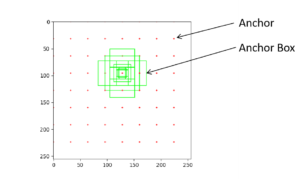
このAnchor Boxの大きさは、scalesとaspect ratioによって決まります。scalesは矩形を形成する基準の長さ、aspect ratioはその矩形の長さを変える比率になります。
このAnchor Boxが検出したい物体を囲うように形成され、物体の候補領域を見つけに行く仕組みとなっています。今回は、AnchorおよびAnchor Boxを作成するまでを解説します。
3. Anchor Generatorの動作
torchvisionではAnchor Generatorというクラスがあります。このクラスでAnchorやAnchor Boxが作られます。
このAnchor Generatorの動作内容はこのようになっています。
- 1. base anchorの作成
- 2. grid sizesの定義
- 3. stridesの定義
- 4. grid_anchorsの作成
3-1. base anchorの作成
まず初めにbase anchorを作成します。これは、scalesとaspect ratiosによって変わるものになります。いわゆる矩形のパターンを決める座標情報です。
前述しましたが、scalesはAnchor Box(矩形)を形成する基準の長さです。aspect ratiosはscalesの大きさを変える比率のことです。
今回の場合、scales (16, 32, 64)、aspect ratios(0.5, 1.0, 2.0)としています。
torchvisionでは下記のようなコードでbase anchorsを作成しています。
def generate_anchors(self, scales: List[int], aspect_ratios: List[float], dtype: torch.dtype = torch.float32,
device: torch.device = torch.device("cpu")):
scales = torch.as_tensor(scales, dtype=dtype, device=device)
aspect_ratios = torch.as_tensor(aspect_ratios, dtype=dtype, device=device)
h_ratios = torch.sqrt(aspect_ratios)
w_ratios = 1 / h_ratios
ws = (w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h_ratios[:, None] * scales[None, :]).view(-1)
base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2
return base_anchors.round()
aspect ratiosはこのままの形で使用するのではなく、平方根を取っています。なぜなら、各基準の長さ毎にAnchor Boxの面積(ピクセル数)を揃える必要があるからです。
scales(16, 32, 64)、aspect ratios(0.5, 1.0, 2.0)の場合のbase anchorsはこのようになります。
tensor([[-11.3137, -5.6569, 11.3137, 5.6569],
[-22.6274, -11.3137, 22.6274, 11.3137],
[-45.2548, -22.6274, 45.2548, 22.6274],
[ -8.0000, -8.0000, 8.0000, 8.0000],
[-16.0000, -16.0000, 16.0000, 16.0000],
[-32.0000, -32.0000, 32.0000, 32.0000],
[ -5.6569, -11.3137, 5.6569, 11.3137],
[-11.3137, -22.6274, 11.3137, 22.6274],
[-22.6274, -45.2548, 22.6274, 45.2548]]
このbase anchorsは、9パターンの矩形が存在することを意味しています。
3-2. grid sizesの定義
次にgrid sizesを定義していきます。grid sizesとは、画像中に設定するAnchorsの点数を示したものになります。
例えば、grid sizesが(8, 8)なら64個のAnchorが存在することになります。
torchvisionの場合、下記のコードでgrid sizesを定義します。
grid_sizes = [feature_map.shape[-2:] for feature_map in feature_maps]
grid sizesは、feature mapの縦横から得られるものになります。feature mapとは、backboneと呼ばれるモデル(Convolutional Neural Network)から得られるものです。
今回、backboneにはmobilenet_v2を使って説明します。例えば、mobilenet_v2では256×256の画像を入力した場合、8×8のfeature mapが出力されます。
つまり、grid sizesは(8, 8)になります。もちろん入力画像のサイズが変われば、grid sizesも変わります。
grid sizesが定義されるイメージはこのようになります。

3-3. stridesの定義
次にstridesを定義していきます。stridesとは、画像中にAnchorsを設定するときの間隔になります。
torchvisionの場合、下記のコードでstridesを定義します。
strides = [[torch.tensor(image_size[0] // g[0], dtype=torch.int64, device=device),
torch.tensor(image_size[1] // g[1], dtype=torch.int64, device=device)] for g in grid_sizes]
画像のサイズからgrid sizeを割った値がstridesになります。
例えば、画像のサイズが256×256の場合、grid sizesが(8, 8)となるため、stridesは(32, 32)となります。
3-4. grid anchorsの作成
最後にgrid anchorsを作成していきます。これは、実際に画像中で作成されるすべての矩形を形成するための座標情報になります。
grid anchorsを作成する際の注意点は、grid sizesの数とstridesの数とbase anchorsの数を合わせることです。
今回の場合、それぞれの設定値は下記となります。
grid_sizes: [torch.Size([8, 8])]
strides: [[tensor(32), tensor(32)]]
base_anchors: [tensor([[-11., -6., 11., 6.],
[-23., -11., 23., 11.],
[-45., -23., 45., 23.],
[ -8., -8., 8., 8.],
[-16., -16., 16., 16.],
[-32., -32., 32., 32.],
[ -6., -11., 6., 11.],
[-11., -23., 11., 23.],
[-23., -45., 23., 45.]])]
もし数が一致しない場合は、下記のようなエラーが起きます。
if not (len(grid_sizes) == len(strides) == len(cell_anchors)):
raise ValueError("Anchors should be Tuple[Tuple[int]] because each feature "
"map could potentially have different sizes and aspect ratios. "
"There needs to be a match between the number of "
"feature maps passed and the number of sizes / aspect ratios specified.")
grid anchorsはbase anchorsとanchorsを足し合わせることで作成されます。anchorsとは矩形を形成するための中心となる座標情報です。base anchorsはscalesとaspect ratioから作成される矩形を形成するための座標情報になります。
grid anchorsを具体的に示すとこのような座標情報を持ったものになります。
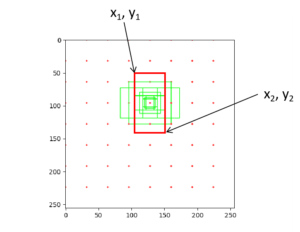
[x1, y1, x2, y2]という座標情報を複数持ったものがgrid anchorsになります。今回の場合、anchorの数が64個、base anchors(矩形のパターンの数)が9個あるので、grid anchorsは576個の座標情報を保持していることになります。
torchvisionの場合、下記のコードでgrid anchorsを作成します。
(shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4)
shiftsはanchorsのことです。それにbase anchors(矩形のパターン)を足し合わせることでgrid anchorsを作成しています。
grid anchorsを一部抜粋して示すとこのようになります。
[tensor([[-11., -6., 11., 6.],
[-23., -11., 23., 11.],
[-45., -23., 45., 23.],
...,
[218., 213., 230., 235.],
[213., 201., 235., 247.],
[201., 179., 247., 269.]])]
上3つは原点(0, 0)がanchorの場合の座標情報になります。
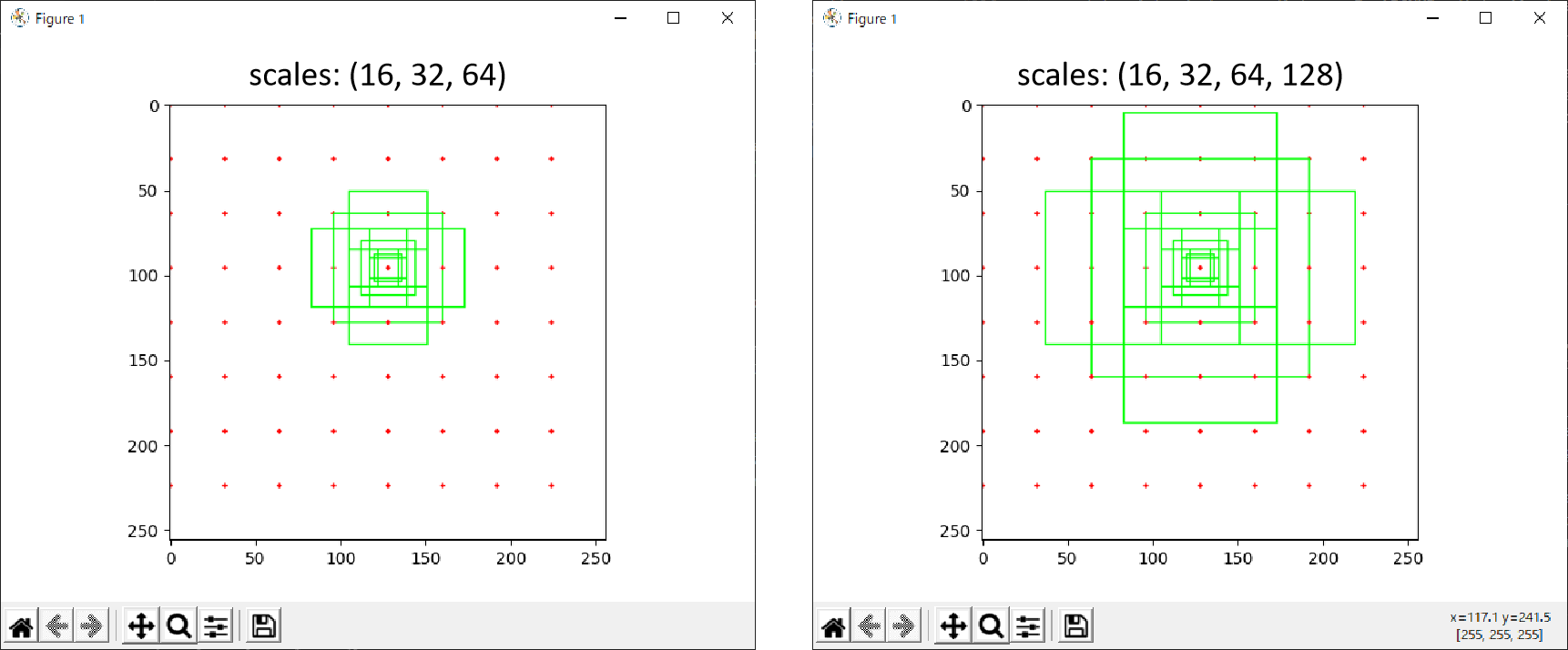
おまけ(scalesを変えることで理解を深める)
今回はscalesを(16, 32, 64)として説明してきました。このscalesを(16, 32, 64, 128)とした場合、もちろん矩形のパターンが変わります。
まとめ
torchvisionのFaster rcnnのAnchorという概念について説明しました。
Anchorによって物体を囲う候補領域を見つけることができます。もちろん、これだけではFaster rcnnによる物体検出はできないので、今後はRegion Proposal Networkについても理解していきたいと思います。